Platform Reliability Intelligence for distributed enterprise systems.
Monitor distributed pipelines, detect failures faster, perform AI-powered root cause analysis, and resolve incidents through conversational operational intelligence.
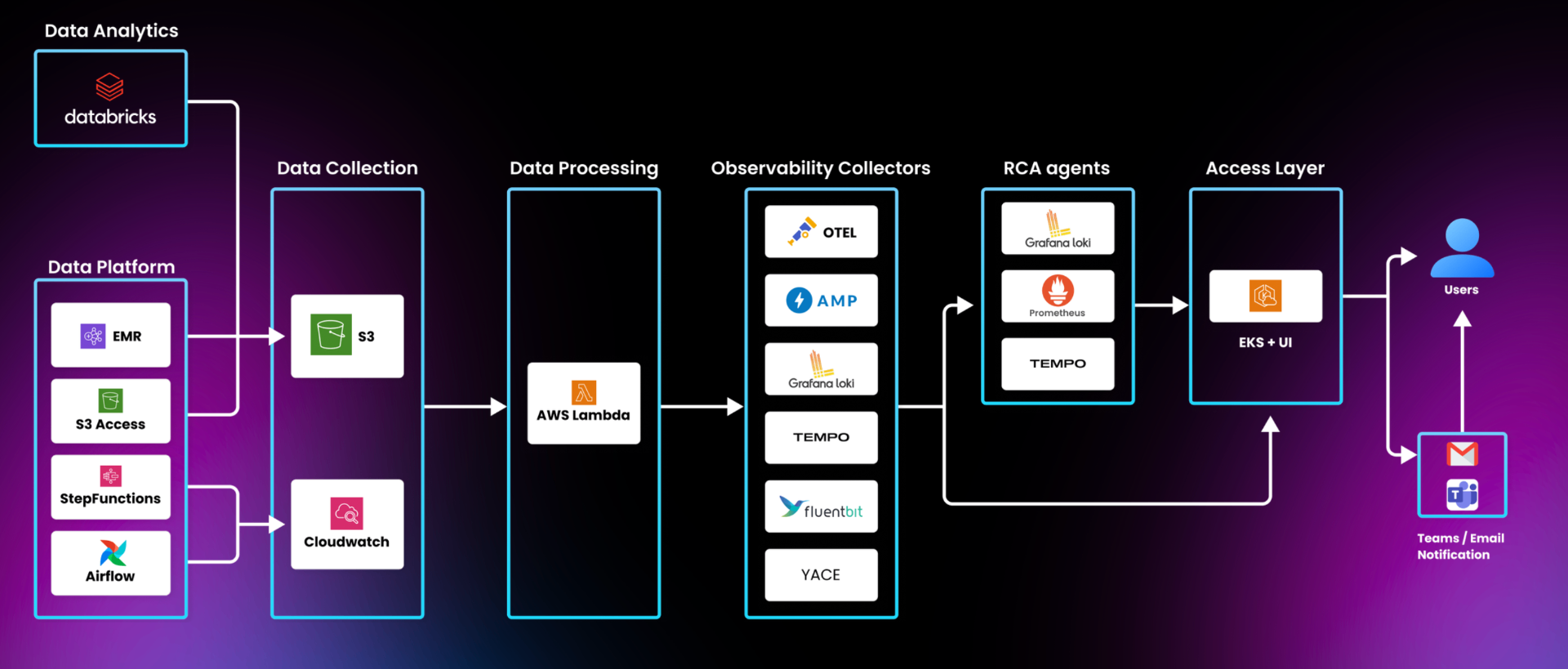
Modern data platforms are increasingly fragile.
Enterprises run thousands of interconnected pipelines, APIs, and AI workflows. Traditional observability generates alerts — but rarely operational intelligence.
AI-driven reliability operations.
A continuous loop: detect, investigate, resolve, prevent.
- AI-powered real-time failure detection
- Predict issues before pipeline impact
- Cross-signal anomaly detection across distributed pipelines
- Correlate signals across distributed systems
- Pinpoint exact root cause in minutes
- Natural-language queries for RCA
- Guided, step-by-step remediation
- Auto-generated runbooks from past incidents
- Code and workflow automation with Agentic AI
- AI-driven failure prediction
- Recommendations to prevent recurrence
- Continuous learning from every incident
A unified intelligence layer across your entire reliability ecosystem.
Conversational AI for root cause analysis.
Ask your platform what went wrong — get answers instantly.
Smarter, faster, cheaper.
Purpose-built for distributed platform reliability.

Driving measurable operational impact.
Built for modern enterprise platforms.
How ClairAI stands apart.
A side-by-side look at how ClairAI compares to leading observability platforms on the capabilities that actually drive reliability outcomes.
| Feature | ClairAI | Product X | Product Y | Product Z |
|---|---|---|---|---|
| Unlimited accounts | ||||
| Unlimited log & metrics ingestion | ||||
| Auto pipeline discovery | ||||
| Native Databricks monitoring | ||||
| AI root cause analysis | Included | $5–15K extra | Add-on | $5K+ extra |
| Unified logs + metrics + traces | Partial | |||
| Flat licensing (no per-host) | ||||
| Cost transparency dashboard | ||||
| On-prem deployment option | ||||
| AWS Managed Prometheus (AMP) | ||||
| AWS Managed Grafana (AMG) | ||||
| Public self-serve pricing |
Trusted by teams running mission-critical platforms.
"ClairAI cut our MTTR from hours to minutes. The conversational RCA is the first AI feature my SREs actually use every day."
"We replaced four monitoring tools and reduced alert volume by 70% in the first quarter. Our on-call engineers can finally sleep."
"Auto pipeline discovery onboarded our entire AWS estate in a single afternoon. The Prometheus cost savings alone paid for the platform."
Insights for reliability leaders.
Whitepapers, thought leadership, and deep-dive blogs from the ClairAI research team.
Transparent enterprise pricing.
No per-host. No per-query. No hidden observability costs.
- Everything in Starter
- Enhanced monitoring
- Operational dashboards
- Priority support
- Everything in Standard
- Full enterprise integrations
- Advanced customization
- Dedicated support
Frequently asked questions.
Everything teams ask before adopting ClairAI — answered.